
在LLM大模型的实践应用中,通过LLM模型对本地知识库做管理和内容提取问答是非常合理且有价值的应用场景。本文将结合自己在学习Langchain及Langchain-Chatchat过程中的实践,做如下记录:
主要分以下三部分:
- 环境准备
- ubuntu 22.04, python 3.11, conda
- cuda 12.2 + GPU;本文使用Nvidia L40做测试
- 模型下载
- 安装部署
- 克隆langchainchatchat代码
- 安装依赖
- 数据和配置初始化
- 启动应用
- 功能验证测试
- 打开部署好的应用地址 http://localhost:8501
- 基于chatglm3-6b的对话验证
- 上传文档的问答
- 基于知识库的文档
- 实践中遇到的问题
环境准备
安装anaconda3 for linux
使用conda create -n py311 python=3.11
conda activate py311
使用nvidia-smi确认GPU是可以的
模型下载,使用bge-large-zh · 模型库 (modelscope.cn)
vim model_download.py
#模型下载 from modelscope import snapshot_download
model_dir = snapshot_download(‘AI-ModelScope/bge-large-zh’)
model_dir = snapshot_download(‘ZhipuAI/chatglm3-6b’)
python model_download.py
模型下载到/root/.cache/modelscope/hub目录
验证模型加载:
import torchfrom langchain.chains import LLMChainfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.chains.mapreduce import MapReduceChainfrom langchain.prompts import PromptTemplatefrom langchain.llms.base import LLMfrom transformers import AutoTokenizer, AutoModel, AutoConfigfrom typing import Any, Dict, List, Mapping, Optional, Tuple, Unionfrom torch.mps import empty_cachefrom transformers import AutoModelForCausalLM, AutoTokenizerfrom transformers.generation.utils import GenerationConfig
class GLM(LLM):max_token: int = 2048temperature: float = 0.8top_p = 0.9tokenizer: object = Nonemodel: object = Nonehistory_len: int = 1024def __init__(self):super().__init__()@propertydef _llm_type(self) -> str:return “GLM”# 传入模型的路径def load_model(self, llm_device=”gpu”,model_name_or_path=None):#tokenizer = AutoTokenizer.from_pretrained(“./chatglm2-6b”, trust_remote_code=True)#model = AutoModel.from_pretrained(“./chatglm2-6b”, trust_remote_code=True).cuda()model_config = AutoConfig.from_pretrained(model_name_or_path,trust_remote_code=True)self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,trust_remote_code=True)self.model = AutoModel.from_pretrained(model_name_or_path, torch_dtype=torch.float16, config=model_config, trust_remote_code=True).half().cuda()def _call(self,prompt:str,history:List[str] = [],stop: Optional[List[str]] = None):response, _ = self.model.chat(self.tokenizer,prompt,history=history[-self.history_len:] if self.history_len > 0 else [],max_length=self.max_token,temperature=self.temperature,top_p=self.top_p)return response
结果:
安装部署
- git clone https://github.com/chatchat-space/Langchain-Chatchat.git
- 按照READEME.md
- pip install -r requirements.txt
- pip install -r requirements_api.txt
- pip install -r requirements_webui.txt
- pip install jq
-
“`shell$ python copy_config_example.py$ python init_database.py –recreate-vs“`
- 修改configs/model_config.py
- EMBEDDING_MODEL = “bge-large-zh”
- model path/embed_model: “bge-large-zh”: “/xxxxxx/BAAI/bge-large-zh”,
- model_path/llm_model: “chatglm3-6b”: “/xxxxxxx/THUDM/chatglm3-6b”,
- start up
-
“`shell$ python startup.py -a“`如果正常启动则可以访问http://localhost:8501 页面
- 如图所示
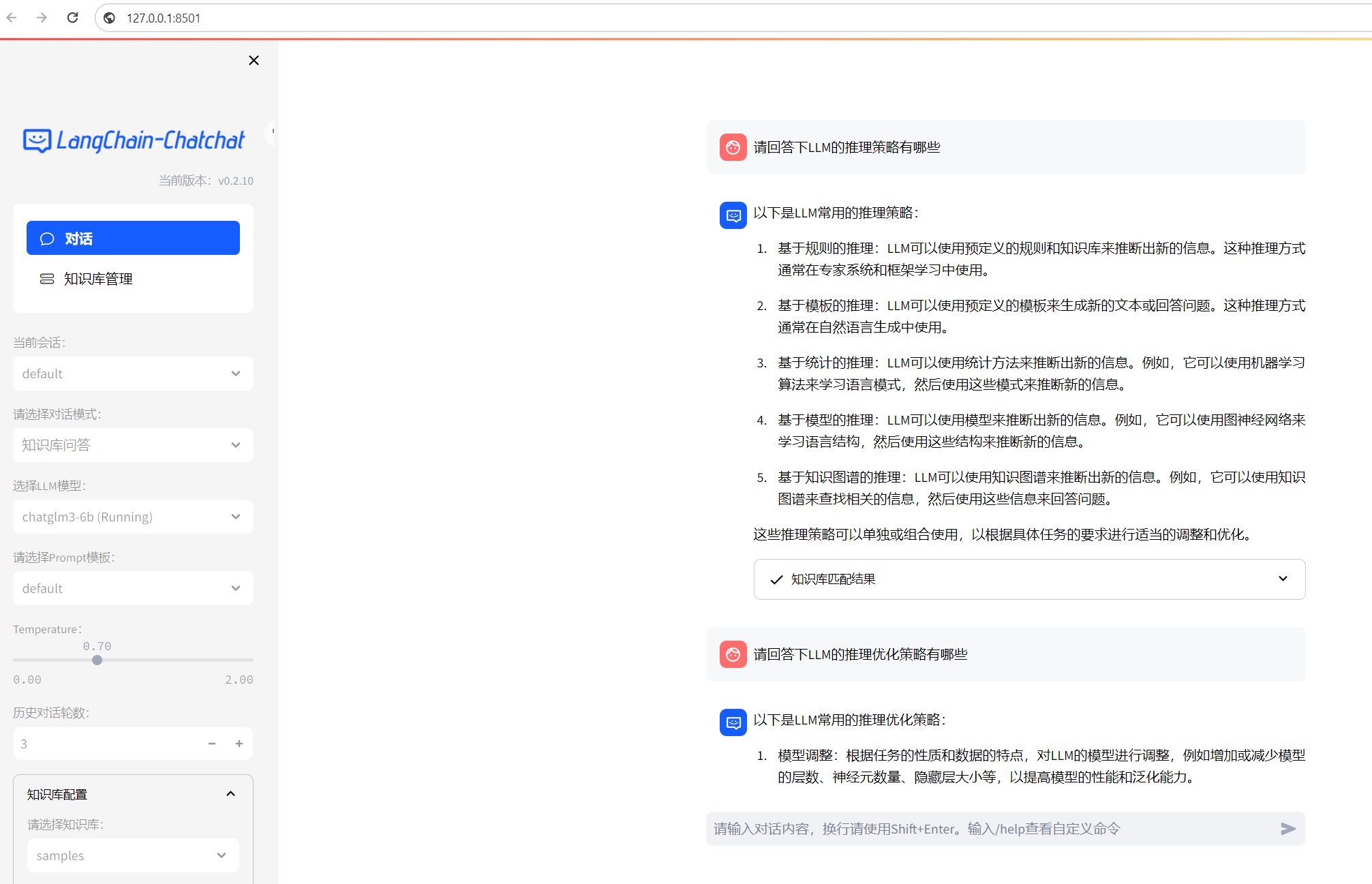
功能验证
可以上传pdf文件做文件文档
也可以通过知识库管理,创建自己的知识库,然后基于自己的知识库做文档
也可以基于chatglm3-6b模型做问答
部署过程遇到的问题:
无法加载模型,总是在model_worker这里出现问题,后来发现是server 127.0.0.1无法启动,原因是使用了代理导致本地服务无法通过localhost或者127.0.0.1调用;
沟通交流合作请加微信!